
BIOT - Biodiversity Information Organized using Taxonomy
About the Project
Brief | Overview .pdf | Project Website | Demo
The BIOT project uses biology's taxonomy as a way to classify and access the small subset of web information on organisms and biodiversity, providing audience-specific information and better precision than Google. Click on a node of the taxonomy to see a list of relevant websites. The information presented at each node of the taxonomy should adjust depending on the audience; thus school students will find common names and content generalized to larger categories on the classification system, while experts will interact with species-specific information and scientific names.
click to enlarge or reduce screenshot
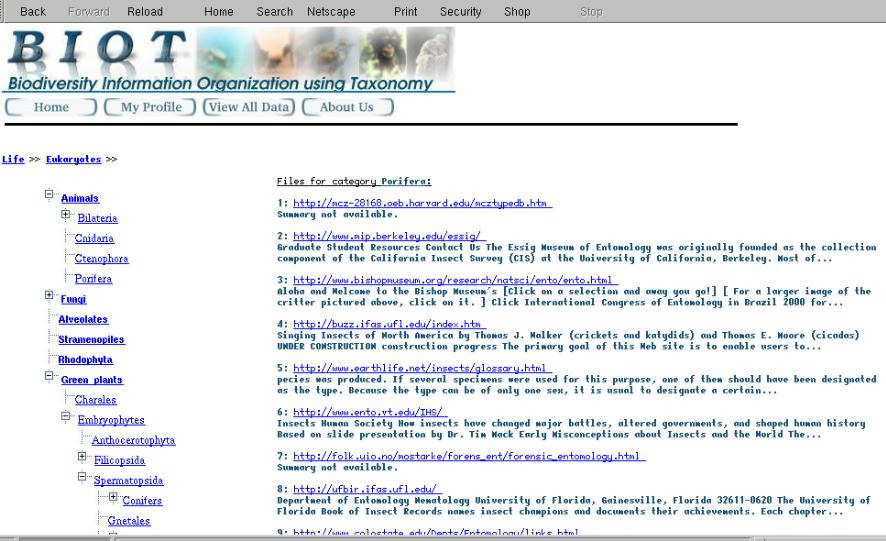
The three main parts of the project include classification, browsing, and adapting. Classification includes developing a spider to search the Web, classify web pages according to the ontology provided by biological classification taxonomy and other criteria to asses the audience, timliness and accuracy of the information. Browsing includes developing an effective way of navigating the taxonomy and retrieving the appropriate web resources.
The demo provides an interactive browsing interface that allows users to navigate a large ontology on a single web page using Dynamic HTML. They can selectively expand and contract nodes for easy navigation. It provids an adaptive interface so that content is matched to user profiles based on readability metrics so that content is hidden that is not accessible to individual users.
BIOT is an NSF grant project under the Biodiversity and Ecosystem Informatics (BDEI) initiative, at the University of Kansas (Information and Telecommunication Technology Center, Nat Hist Museum & National Center for Informatics Biodiversity Research).
Evaluation of Tree Navigation
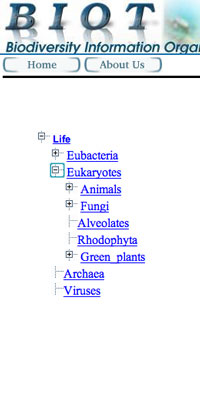
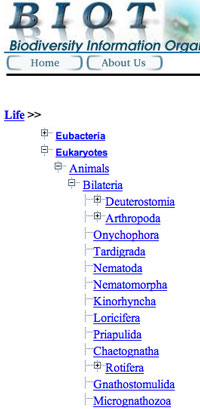
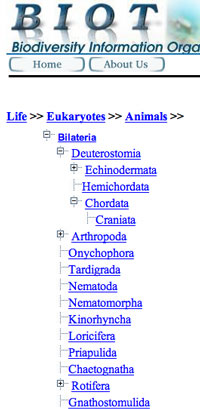
Tree navigation behavior uses the PC file browser conventions that items with plusses have sub-items, or click the minus to hide the listing of sub-items (see screenshots to the left). Because the navigation clicks to open or close the node, the content in the display window to the left does not follow along, until a node label, or a leaf, is actually clicked. Up to four levels of the hierarchy are displayed, while levels beyond that are clickable breadcrumbs. Similar tree displays include GenBank's Taxon browser, and the clustering search engine Vivisimo.
This tree style works nicely, with a major drawback - unless users know where on the tree to find the target of their investigation, they may get stumped by not recognizing intermediate node labels. During our interviews for the MaNIS Interface project, we found that even a wildlife biologist, who works with scientific names for herps all the time, is less familiar with the classification structure for other parts of the tree of life. For example, searching for a genus of bats, identifying the desired node "Chiroptera" is no problem, but one gets stuck not knowing which family to open. Even experts will only know their own part of the tree of life. Thus this tree style is good for open-ended motivated browsing, but less effective for directed browsing and search.
Additional suggestions:
- An indicator on the hierarchy of which link was last clicked, and is therefore showing in the content display window.
- Deactivate hyperlinks on node labels when no data is available for that topic.
- Better handling of what appears in the display window when the user navigates down a different branch of the tree than the last-clicked node is located on.
- Common names
- An indicator on the hierarchy of which link was last clicked, and is therefore showing in the content display window.
- What are the **** trying to indicate?
Other examples using similar navigation include: New Zealand Flora Online |